
This is part II of post looking at Continuous Testing with Adam Sandman.
Tools Recap
We have mentioned some tools in the last post, but just to recap, here are some ideas:
- Dependency checkers – DependencyCheck
- Static Code Analysis – Parasoft, SonarQube
- Unit Tests – xUnit (jUnit, Nunit, PyTest, etc.)
- Performance Tests – JMeter, Gatling, NeoLoad
- API Testing – Postman, Rapise, SoapUI
- Security Testing – OWASP ZAP
- UI Testing – Rapise, Selenium
- Exploratory Testing – SpiraCapture
Shift Right: Monitoring in Production, after CD
In continuous testing, “Shifting Right” refers to continuing to test the software after it is released into production. Also known as “testing in production,” the process can refer to either testing in actual production or a post-production environment.
The key aspect is that Shifting Right is all about leveraging the insights and usage of real customers and access to production data to test effectively and support feedback loops.
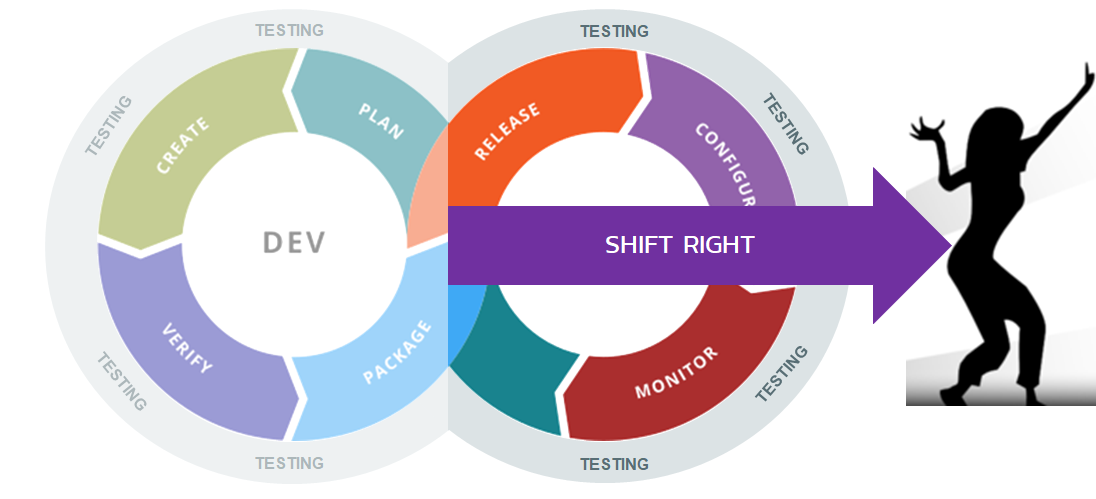
Shift Left testing relies on trying to find problems early with fast, repetitive testing that uncovers areas of risk and tries to prevent problems occurring. Shift Right testing, on the other hand, involves monitoring user behaviour, business metrics, performance and security metrics, and even deliberate failure experiments (chaos testing) to see how resilient the system is to failures.
Continuous Deployment (CD)
In agile projects, Continuous Integration (CI) means that you are continuously integrating and testing the code so that it could be theoretically be deployed into production at any time. However, Continuous Deployment (CD) takes this one step further and automates the process of actually deploying the code into production in an automated fashion. Usually, with CD environments, because you are reducing or eliminating the manual “go / no-go” decision process, there should be a way to seamlessly roll back the update just as easily.
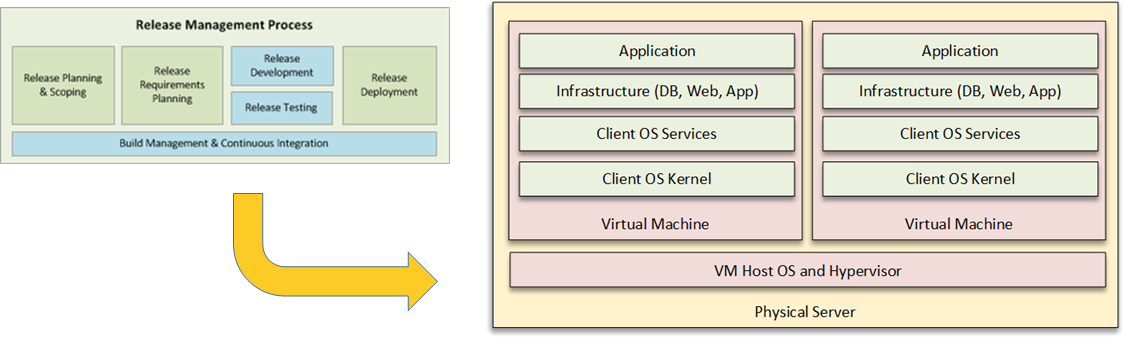
With CD, a lot depends on the type of application being deployed (SaaS, PaaS, on-premise, etc.) and the infrastructure in place (physical, virtual, containerized, cloud, etc.), however in general, CD is all about automating the process from being release-ready (CI), tests passed, to being actually released into production, with post-release checks in place.
Post Release Testing
Once you have released the system into production, testing does not end. You will need to perform a variety of post-release tests:
- Post-Release Automated Checks
- Usability & Experience Testing
- A/B and Canary Testing
Post-Release Automated Checks
Once the code changes have been deployed into production, you should automatically run a set of non-destructive, automated functional tests that test that the code released into production behaves functionally the same as what was tested in development. This may sound obvious, but it is amazing how many times different configurations used in production (higher security, higher availability, etc.) can cause the system to behave differently.
You can usually take your existing automated unit tests and run a subset of them against production. You have to be careful because you are dealing with live customer data, so some automated tests will have to be modified or excluded because of how they would change live data.
Usability & Experience Testing
Shift-right testing also is concerned with the business value and usability of the updated version, i.e., do the new user stories make the system better for the users. Even though the system is now live, you can still perform usability and experience testing to make sure that users can understand any UI changes and that the system has not degraded the experience. Two techniques for measuring this are A/B testing and Canary Testing.
A/B and Canary Testing
In the world of digital marketing, A/B testing is a very common technique that is now being “borrowed” in the world of software development and DevOps. You basically divide up your customers into two groups (“A” and “B”). Half of the users get the old version of the system (“A”), and the other half get the new version of the system (“B”). This means your CD system needs to be able to deploy to specific regions or instances at different cadences. You can then survey or measure users’ interactions with both versions. For example, in an e-commerce system, you could measure what % of new prospects purchase a product using the two versions of the system.
A variation of “A/B testing is “Canary Testing” so-called because it mirrors the idea of the canary in the coal mine that alerts miners to the first presence of the poison gas. With Canary Testing, you push the latest update to just a small community of users that you know which react quickly to any changes. For example, you might have an “early adopter” update channel that motivated users can subscribe to.
Monitoring
In addition to post-release testing (which tends to happen immediately after pushing code into production), continuous monitoring is the other aspect of “Shift Right” testing that needs to be put in place, both system, and business metric monitoring.
System Monitoring
Many of the non-functional testing tools used in Shift Left testing (load, performance, security, etc.) have analogous tools that are used for monitoring (performance monitoring, security monitoring, etc.) the same metrics in production.
So once the code has been pushed into production, you should ideally have a system monitoring dashboard that lets you see the key metrics (security, performance, etc.) from the live system in real-time. There are subtle differences, for example, performance monitoring focuses on checking the system response time, CPU utilization, etc., under the current load, vs. generating load to see when problems occur.
Business Monitoring
In addition to system metrics, you can learn a lot about a system by monitoring the various business metrics and correlating them together. For example, if you have a website that tracks signups (conversions) and actual sales (revenue/orders), you can measure the ratio of the two metrics (sales conversion rate), and if you were to get a sudden drop in this rate after a code push, you would quickly know to check the user flow to make sure a bug has not been introduced that prevents a user completing a sale.
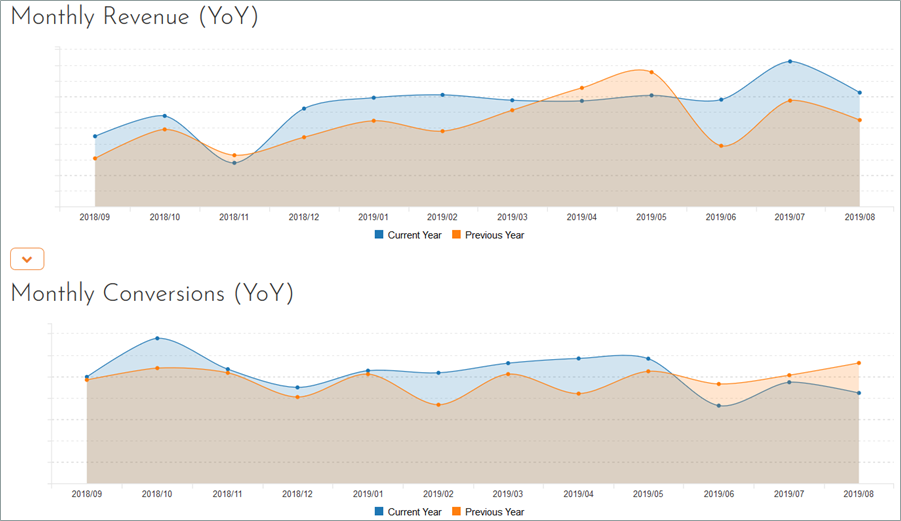
In this way, business metrics can be a useful indicator of a problem that system monitoring may have missed! In addition, monitoring different business metrics can be used to “test” the business value of system changes. For example, a change that makes the application faster but ends up generating less valuable orders might be desirable for users, but not for the company!
User Monitoring & Feedback
Another important source of feedback on a system release is users. Therefore, your customer support system (help desk, service management solution (ITSM), etc.) is an important source of feedback data. If you have accidentally introduced a new defect or functionality regression, your users will let you know quickly.
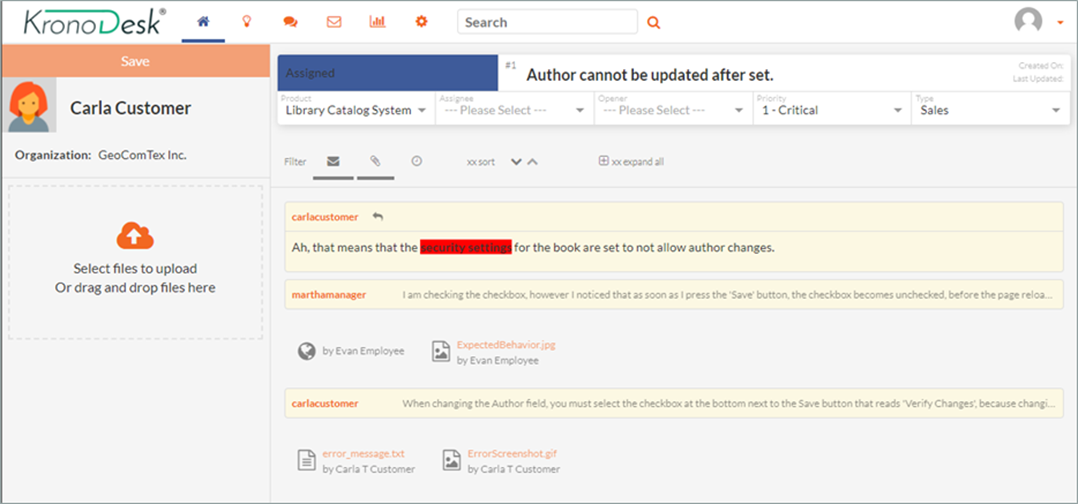
If you start seeing a trend from trusted users raising support tickets about a specific issue, you can immediately have a ‘tiger team’ do an investigation and get a hotfix into the CI/CD pipeline, or if serious enough, you can potentially rollback the change before it affects other users.
Chaos Engineering & Self-Healing
Finally, one relatively innovative approach taken by some companies (most notably Netflix with its Chaos Monkey) is to have an automated agent that deliberately (and randomly) terminates instances in production to ensure that engineers implement their services to be resilient to instance failures.
If you decide to implement Chaos Engineering, you will need to ensure you have developed real-time monitoring and “self-healing” services that detect the failures and can have the system adapt to them in real time. For example, you could have the infrastructure spin up additional resources, route traffic around the degraded instances, and take other protective and reactive measures.
Tools Recap
We have mentioned some tools in the previous sections, but just to recap, here are some ideas:
- System Monitoring
- Performance – Dynatrace
- Security – Solarwinds, Cloudwatch
- Customer Helpdesk – ZenDesk, KronoDesk, Remedy, etc.
- Customer Behavior – Google Analytics, Splunk, Matomo
- Business Monitoring
- Traditional BI Platforms – PowerBI, Splunk, Cognos, Domo, etc.
- AI-Driven Data Analytics – Qlik, Tellius, etc.
- Data Visualization – Tableau, etc.
- Customer Satisfaction – Delighted, Promoter, AskNicely, …
Assessing Risk and Deciding Whether to Go Live
The final part of Continuous Testing is the part in the middle: in between rapid testing that identifies risks and uncovers areas to test further, and releasing them into production is the part where you evaluate all of the test results and decide whether to go live.
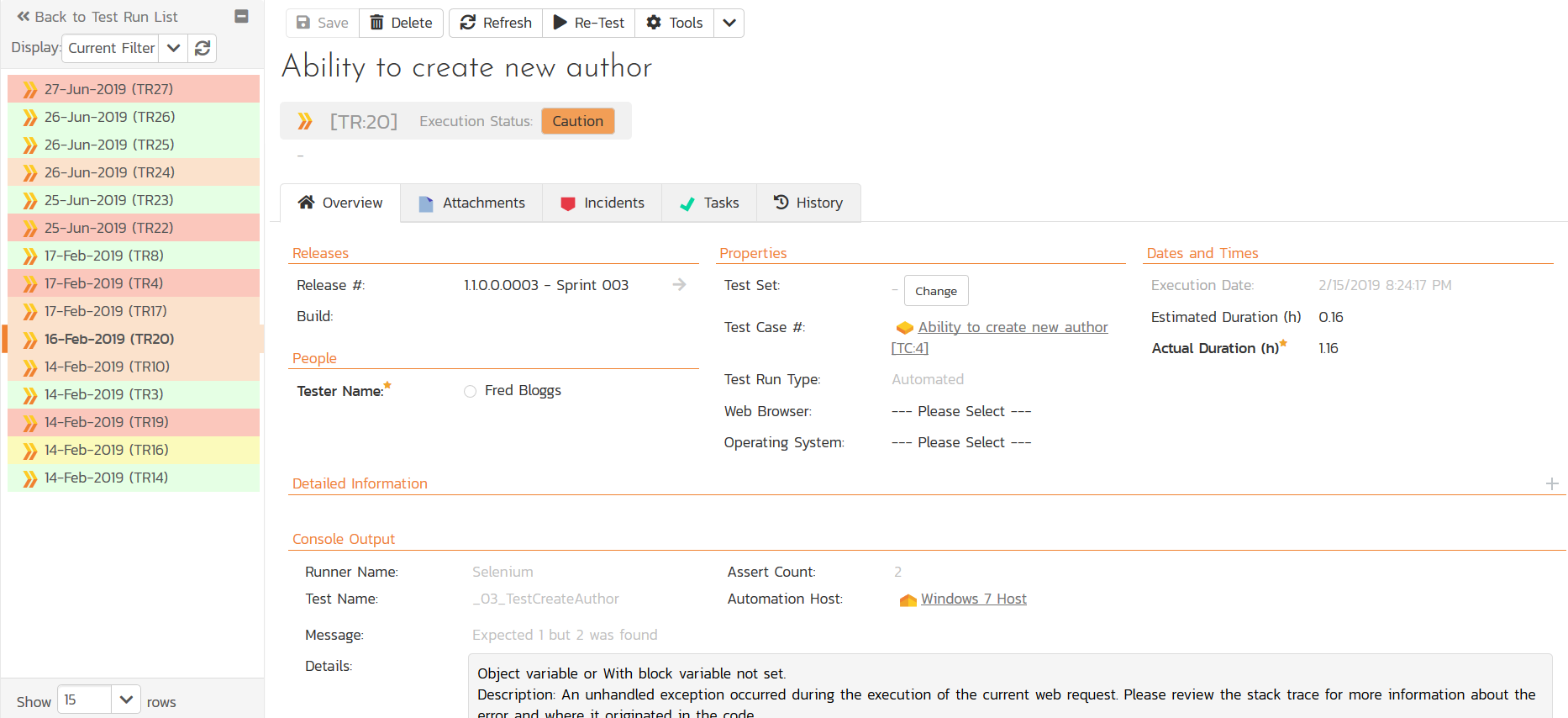
In a true Continuous Deployment (CD) system, you may have automated the part where the DevOps infrastructure pushes code into production, but even so, you will need to have codified the rules to determine when the system is “stable enough” for release. In a traditional “manual” release process, you have a human manager reviewing the testing information and making a decision to go live.
In either case, you are going to have to answer the following two questions:
- How Do We Know if We Can Release into Production?
- How Do We Know We Have Tested the Right Areas?
We Don’t Have Enough Time to Test Everything!
The reality is that whether manual or automated, you will not have enough time in an agile, CI/CD environment to retest every part of the system 100% with all your tests. If you use a combination of Shift-Left techniques to know where to focus, deeper testing in the middle to explore those areas, and Shift-Right to be able to identify and recover quickly from a problem, then the key is to understand at what point do you have enough data to determine that the risk from releasing is less than the risk from not releasing.
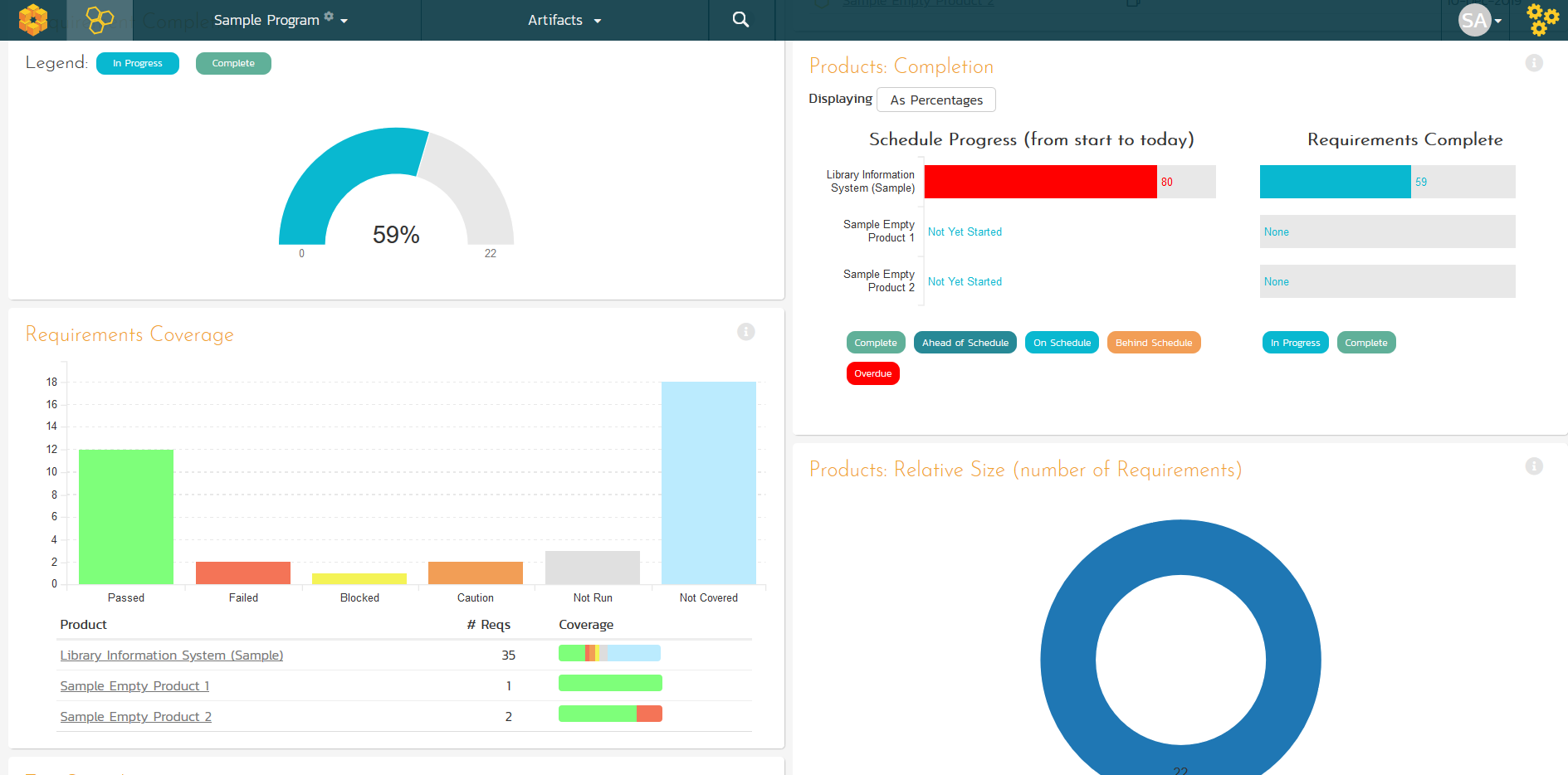
That does not mean there is zero risk from a bug, just that the risk of a bug occurring is less critical than the risk that existing bugs remain unfixed and that the business risk of delaying that feature is greater than the business risk of an issue that impacts users.
Conclusion
In conclusion, when you are looking to incorporate Continuous Testing practices into your DevOps process, these are the three areas you will need to prioritize and plan for:
- Integrate Shift-Left techniques into your CI Pipeline. Address risk areas identified early to focus deeper testing
- Add Shift-Right techniques into your post-deployment infrastructure so that testing doesn’t end after live
- Have a risk-based approach to deciding when to release functionality into production