
Achieving the high software quality is, unfortunately, still hard to attain. One important reason is that IT industry loves tools, automatization and software solutions. We think that new technologies will immediately solve our problems – just because. Having no real, rational arguments for that, we believe that all this stuff is a silver bullet or some other software quality snake-oil. We love this illusion that high complexity of modern technologies immediately implies their high robustness and applicability. In all this madness of unceasing progress of technology we have somehow lost the ability to have a deeper reflection about the foundations of our craft. And also, the ability to transform this reflection into a working solution, which in many cases can be much more effective than just relying on a new tool or a sophisticated tchnology.
Let us follow this apparently underestimated approach and return to the roots of the testing craft. Starting with the fundamental principle – a reflection on how software works – we will identify the software’s primary ‘components’ (hereinafter called software dimensions). These basic software elements will help us to build a software fault model showing the ways in which software may fail. The model will then guide testing, being a handy tool for providing good, effective and creative test ideas.
Basic Software Characteristics
When we ask someone ‘what does the software really do?’, probably the most frequent answer would be ‘it processes data’. This is perfectly fine: every program accepts some input data, transforms them and outputs other data. This process takes place in time: a program is not able to return the answer immediately – it needs to perform several steps. The actions that our program undertakes are a result of some events that either come from the inside of a software or are external, and come from the environment in which software operates. Data and events can be described quantitatively. For example, data value can be large or small, events can occur frequently or rarely and so on.
We have just come up with four basic software ‘dimensions’: Data (D), Events (E), Time (T) and Quantity (Q). These concepts are very general – notice that any software and its actions can be reduced to, and expressed with only these four basic ideas. We may support this rather strong thesis in the following way: software and computation are part of the physical world. Everything what happens in this world can be described by using several basic properties, like: mass, thermodynamic temperature, time or amount of substance. Consider the following analogies between the physical world and a working software, illustrated in Fig. 1:
- data is like matter – it is a substance that represents information,
- events are like thermodynamics, which describes the transformations of the physical objects,
- time is exactly the time that we know from physics,
- quantity is like the amount of substance.

Figure 1. Relation between physical properties of the world and the software
Our model uses these four entities as a foundation. All other, more complicated ideas and relations will be built on this base. Let us think about how these dimensions may be related to software regarding the testing process:
- Data – input or output data, sent or received message, file, database record, line of code, form field, defined/used variable, attribute, parameter, property, object of a given class, type/kind of software or hardware entity, state etc. Data can be valid or invalid. Data may also represent the internal, implicit entities not given explicitly in the specification.
- Events – any kind of action that comes from the user, environment or SUT: pressing a key, calling a method, executing a statement, system call, error message, throwing an exception, opening or closing the application, a variable becoming the wild or dangling pointer etc.
- Quantity – expresses the amount of something: it may be low or high value, boundary or close to the boundary, maximal possible, minimal possible etc.
- Time – discrete or continuous; may represent the succession or sequences; may describe fast or slow task execution, the amount of time between events, high or low frequency etc.
As our model will be described in terms of these four dimensions, we have to explain why we have decided to define software in such a way. The fundamental idea behind our model is as follows: if we are able to describe any aspect of any software with these four characteristics, we can also do this for failures and bugs present in the code and documentation. Hence, theoretically, if we are able to describe the software detailed enough, we should be able to identify all the risks, problems, bugs, threats and possible failures.
TQED Model
Having our four basic dimensions in place is not enough. Of course, there may be some error in a file (Data problem), some input string may be too large (Quantity problem), an unexpected exception may occur (Event problem) and so on. But software is more complicated. We need to build a new layer upon our four dimensions. For example, a failure may happen when we use a certain model of a printer together with a certain model of a web browser. Both printer and web browser can be considered as a Data dimension. But the failure results by a combination of these two entities. Hence, we should consider different combinations of dimensions. Together with the basic dimensions they constitute our final model, presented in Fig. 2.
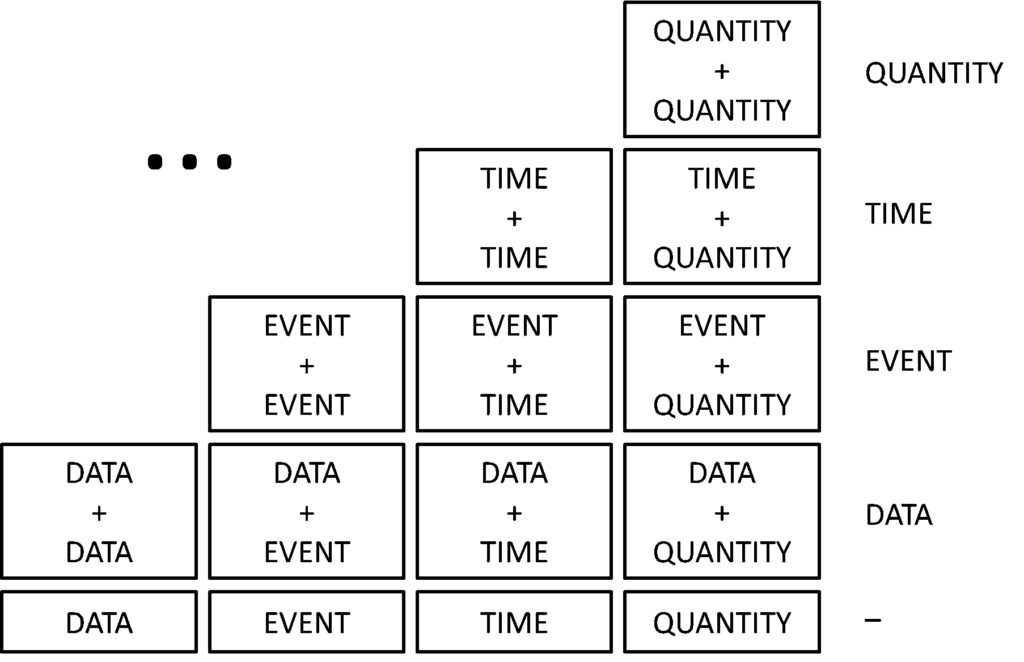
Figure 2. TQED model with basic combinations of dimensions. (C) 2018 Springer International Publishing, reprinted with permission
The grey rectangles represent the basic dimensions and the white ones – combinations of two dimensions. The three dots in the upper left part of the model represent more complicated situations, for example a combination of Data, Quantity and Event.
Like in the case of basic dimensions, let us think now how the combinations of them may be related to a System Under Test. Note that this is just an example – such an analysis should be done for each SUT individually, as each application is different and operates in different environment. Hereinafter the combinations will be represented by the concatenated letters that represent particular dimensions, e.g. DQ means Data+Quantity.
- DD – combination/interaction of data, for example a certain type of printer combined with a certain type of web browser;
- DE – data-driven interaction with user, system or environment, for example creating (event) a new record (data) in a database;
- EE – combination of events, for example: incoming call when using some mobile application or performing another action;
- DT – sequence of operations on data, for example CRUD testing;
- ET – sequence of actions in time/achieving the same goal in different ways, for example in the auto-correction mode in Word you can obtain a different effect when you delete a character and write another one, and when you select a character and write another one;
- TT – time relations between data, events, order of two or more events, concurrency, for example race condition;
- DQ – related to amount of data, for example testing too large values in some field;
- EQ – extreme values for events, e.g. lack of disk space, lack of memory;
- TQ – related to frequency or intensity, for example soak testing;
- QQ – combination of quantities of events or data, for example combinatorial performance testing (e.g. low memory & low disk space).
The name ‘TQED’ is the acronym for the four basic dimensions: Time, Quantity, Event, Data. It may be also derived from the words: ‘Tested. Quod Erat Demonstrandum’ (‘Tested. What was to be demonstrated.’), but of course this interpretation should be treated facetiously.
Model Properties
The TQED model is conceptual. It provides us with some basic notions that can be mapped to some real entities in our test project. Analysis of these notions and their combinations allows us to perceive very concrete risk areas or defect-prone places in a SUT.
The presented approach is also universal: the dimensions themselves are only abstractions, hence they may be used in any kind of test type on any level of abstraction. The method fits in with the unit testing of a single class as well as with the system testing of a piece of hardware. Also, the model can be applied to any kind of a SW/HW test project, as all components of any SUT can be expressed in terms of the four basic software testing dimensions.
It may be advisable to perform the conceptual mapping for more than two dimensions. For example, one may consider combinations like DETQ or DDEQQT. Considering a specific number of combinations should reflect the optimal trade-off between the risk, quality of tests, time and model simplicity. Exploratory testers may use the model as well: it can serve as a practical tester’s roadmap when performing the exploratory testing session. It can also help the tester in inventing valuable ad-hoc tests and in organizing the session in a systematic way.
The TQED model is:
- simple – it uses basic, natural ideas about how software works,
- understandable – it uses comprehensible notions which most IT people are familiar with, so it is easy to remember and understand,
- flexible – it can be used for any kind of software or hardware, for any test level or test type; it can also serve as a test design method,
- generic – it can be narrowed down to a more detailed model (for example, to any of the Whittaker’s software attacks).
Applying TQED in practice: a ticket machine
We will now show how the TQED model can be applied in practice. Assume that we have to perform a system testing of a ticket machine. The only documentation we have is the machine itself and the instruction written on it (see Fig. 3). By pressing two upper buttons a user can change the number of normal and reduced tickets to buy. Pressing ‘Cancel’ zeroes the values. After pressing a ‘Buy’ button a user inserts the coins and/or banknotes to pay for the tickets. The machine gives change. After the payment the tickets are printed and passed over to the dispenser.
Let us apply the TQED approach for this SUT. We will not perform the full analysis, as it would take too much space. Instead, to show how one can benefit from the model, we will focus on some nontrivial test cases that can be derived using the TQED approach.
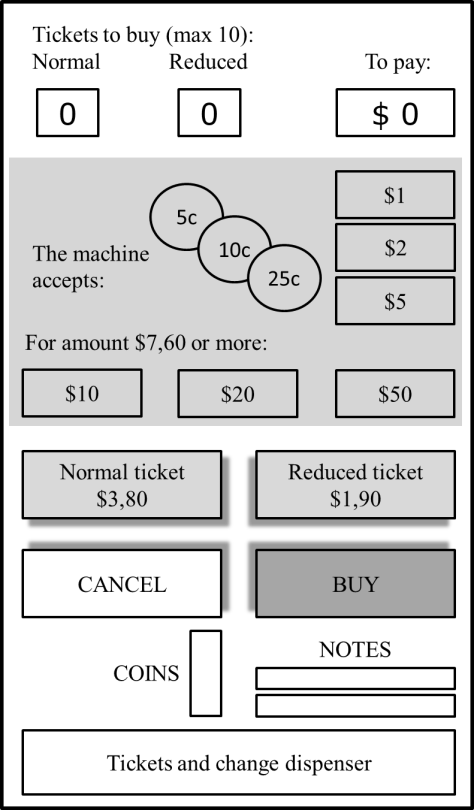
Figure 3. A ticket machine. (C) 2018 Springer International Publishing, reprinted with permission
First, let us identify some real entities related to the basic dimensions. This is shown in Fig. 4.

Figure 4. Real entities for a ticket machine mapped to the basic software dimensions.
Now, let us provide some examples of the non-trivial test cases by analyzing several compositions of dimensions. The process of creating the test ideas is presented in Fig. 5: a tester takes one or more objects from different dimensions and thinks about how they can be combined together to produce a valuable test idea.
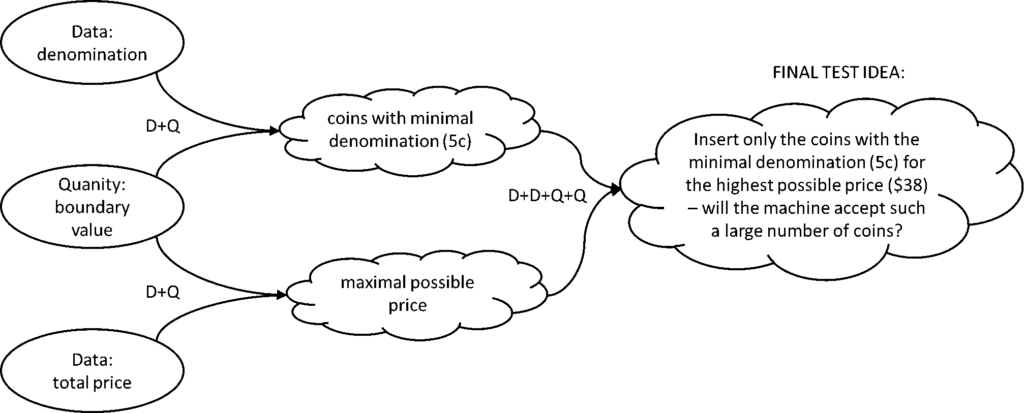
Figure 5. Schematic process of deriving the test ideas using the TQED model.
In Fig. 6 we show some more nontrivial examples. The first column shows the abstract combinations of dimensions. The second one describes the mapping to the real entities of a SUT. The last one contains the test ideas related to the given combinations of dimensions.

Figure 6. Using the TQED model to derive some more nontrivial test ideas.
Theoretically, one can analyze all the combinations for all the mapped entities up to a given number of basic dimensions and therefore derive in a simple, almost mechanical way, quite strong and nontrivial test ideas – which, in my opinion, is the most important task for a tester. The number and types of combinations and tests is of course a matter of many factors, like risk analysis, available resources, test strategy and so on.
Conclusions
It must be remembered, though, that the TQED model is just a proposition of an organized test approach. It is by all means no silver bullet for testing. It supports the tester in a testing process, imposes an organized, engineering approach, but does not excuse a tester from thinking. Software decomposition, choosing the right level of abstraction, prioritizing the tests according to the risk analysis and mapping the dimensions and their combinations to the real entities – all of them are the creative parts and cannot be automated.

More examples and details about the TQED model and – in general – about why thinking is the most important thing in software testing, can be found in my book ‘Thinking-Driven Testing. The Most Reasonable Approach to Quality Control’.
Link: https://www.springer.com/gp/book/9783319731940
Summary of the article
In this article I present a simple and universal model, founded on the natural software testing characteristics, that may help the testers to construct the effective tests by a careful analysis of how system under test (SUT) works and how it can fail. The method may be really useful if there is no formal documentation and the only thing a tester has is a common sense (which is very often the case). A practical example of its application is presented.

Author Bio & photo
Adam Roman, Ph.D., is a professor of computer science at the Jagiellonian University in Cracow (Poland). His research interests include: effective test design techniques, software quality models, mutation testing and application of AI & data mining techniques in software quality engineering. He is an author of two monographs on software testing: ‘Thinking-Driven Testing. The Most Reasonable Approach to Quality Control’ (in English) and ‘Software testing and quality. Methods, techniques and tools’ (in Polish). A proponent of rational acting based on logical and system thinking.