
Today, Kubernetes serves as the basis for modern cloud-native architectures, but it is just one of several components. Framework teams would need new components and methodologies to effectively operationalize the entire stack to unlock cloud-native agility. When it comes to managing multi-cluster Kubernetes through multiple cloud providers, many enterprise IT teams face production challenges. This blog provides you a summary of what you can learn while codifying multiple cloud operations by using GitOps on AWS (Note: GitOps differs from DevOps. Here is a brief explanation of what GitOps is). You will comprehend the topics such as Operator pattern, Custom Resource Definitions that you will use, understanding the concepts of controllers, deployments status, multi-cloud with GitOps, and multiple clusters in GitOps. Get this salesforce cloud computing training course available online to get the practical experience to work with GitOps on AWS for implementing multiple-cloud operations.
Operator pattern
Operators are Kubernetes application plugins that use custom tools to handle apps and their modules. Kubernetes concepts, especially the control loop, are followed by operators. The Operator pattern exploits the primary objective of a human operator responsible for a service or group of services. Human operators responsible for particular software and services have a detailed understanding of how the system should work, how to execute it, and how to respond in the event of a problem.
People who use Kubernetes to run workloads often choose to automate tasks that are repeated. The Operator pattern captures how you can write code to automate a task in addition to what Kubernetes offers.
Operators in Kubernetes
Kubernetes was built with automation in mind. Kubernetes comes with a lot of built-in automation right out of the box. You will use Kubernetes to simplify the deployment and execution of workloads, as well as the way Kubernetes does it.
The controllers’ principle in Kubernetes allows you to expand the behaviour of the cluster without changing the Kubernetes code. Operators are Kubernetes API clients that function as Custom Resource controllers.
Deploying Operators
Adding the Custom Resource Concept and its related Controller to the cluster is the most common way to deploy an Operator. Normally, the Controller would operate outside of the control plane, just like every other containerized program. For instance, you can run the controller as a Deployment in your cluster.
Using an Operator
Once you’ve deployed an Operator, you’ll use it by inserting, changing, or removing the type of resource it uses. In the case of the Operator, you’d build a Deployment and then:
kubectl get SampleDB # find configured databases
kubectl edit SampleDB/example-database # manually change some settings
…and that’s what there is to it! The Operator will be in process of executing the improvements as well as maintaining the current operation.
Custom Resources
Custom tools are Kubernetes API extensions. This page explains whether to use a standalone utility versus adding a custom resource to the Kubernetes cluster. It explains how to pick between two approaches for incorporating custom tools.
Custom Resource Definitions
You can describe custom resources with the Custom Resource Definition API resource. When you identify a CRD object, it generates a new custom resource with the name and schema you chose. The Kubernetes API is responsible for serving and storing your custom resource. A valid DNS subdomain name must be the name of a CRD object.
This removes the need to write your API server to manage the custom resource, but the architecture is more standardized than API server aggregation, restricting the versatility.
For an overview of how to register a new custom resource, deal with instances of your new resource type, and use a controller to manage events, see the custom controller example.
Controllers
A control loop is a non-terminating loop in robotics and automation that controls the state of a machine.
Controllers are control loops in Kubernetes that track the state of your cluster and make or request changes as appropriate. Each controller attempts to get the cluster’s current state closer to the target state.
Controller pattern
At least one Kubernetes resource class is tracked by a controller. A spec field in these objects reflects the ideal condition. The resource’s controller(s) are responsible for bringing the present state closer to the target state. The controller can operate directly; but, in Kubernetes, a controller is more likely to send messages to the API server that have useful side effects.
Ways of running controllers
The kube-controller-manager contains a series of built-in controllers for Kubernetes. Significant core behaviors are provided by these built-in controllers.
Kubernetes provides controllers including the Deployment and Job controllers (“built-in” controllers). Kubernetes allows you to operate a resilient control plane, which means that if one of the built-in controllers fails, another component of the control plane takes over.
To expand Kubernetes, you will find controllers that operate beyond the control plane. You can also build your controller if you choose. Your controller can be run as a group of Pods or outside of Kubernetes. What works better for the controller can be determined by its capabilities.
Deployments
Declarative updates for Pods and ReplicaSets are provided by a Deployment. In a Deployment, you assign the desired state, and the Deployment Controller eventually adjusts the current state to the desired state. Deployments may be used to build new ReplicaSets or to uninstall current Deployments and replace them with new Deployments.
Deployment status
Throughout the lifecycle of deployment, it goes through many stages. It can be complete, it can be progressing while rolling out a new ReplicaSet, or it can fail to progress.
Progressing Deployment
Kubernetes labels a Deployment as “progressing” until one of the following activities is completed:
- A new ReplicaSet is generated by the Deployment.
- The Deployment’s newest ReplicaSet is being scaled up.
- The Deployment is reducing the scale of its older ReplicaSet (s).
- New Pods become ready or available (ready for at least MinReadySeconds)
The kubectl rollout status command can be used to monitor the progress of a Deployment.
Complete Deployment
When a Deployment meets the following criteria, it is marked as “complete” by Kubernetes:
- The Deployment’s replicas have all been upgraded to the new version you specified, implying that any changes you requested have been completed.
- The Deployment’s replicas are all available.
- The Deployment’s old replicas aren’t working anymore.
You will use kubectl rollout status to see if a Deployment is complete. The kubectl rollout status command returns a zero exit code if the rollout was successful.
kubectl rollout status deployment/nginx-deployment
The output is similar to this:
Waiting for rollout to finish: 2 of 3 updated replicas are available…
deployment “nginx-deployment” successfully rolled out
and the exit status from kubectl rollout is 0 (success):
echo $?
0
Failed Deployment
Your Deployment can get stuck while attempting to deploy the most recent ReplicaSet and cannot complete it. This can happen as a result of one or more of the following criteria:
- Inadequate quotas.
- Failures in readiness probes.
- Errors with the image pull.
- Permissions are inadequate.
- Limitations on ranges.
- Misconfiguration of the application at runtime.
Multi-Cloud with GitOps
Multi-cloud/hybrid scenarios are precisely the kinds of scenarios for which the Cluster API was developed. Infrastructure providers offer infrastructure in a target setting, such as the AWS provider (CAPA) or the vSphere provider (CAPV). Infrastructure can be provisioned in a public or private cloud, depending on which provider is chosen, and due to providers like CAPV, they can even be provisioned on-premise (though CAPV isn’t exclusive to on-premise).
In a hybrid or multi-cloud situation, there are a few things to keep in mind:
- The Management Cluster (also known as the Control Plane Cluster) must be able to:
- For Cluster API infrastructure providers to use, keep passwords for each of the target environments.
- Provide enough network access for Cluster API providers to provision their networks, with different specifications for each provider.
- The management cluster, as well as the CAPI services it holds, controls each Workload Cluster (also known as a tenant cluster).
For instance, If we’re going for vSphere on-premises, AWS (multiple accounts), or Azure:
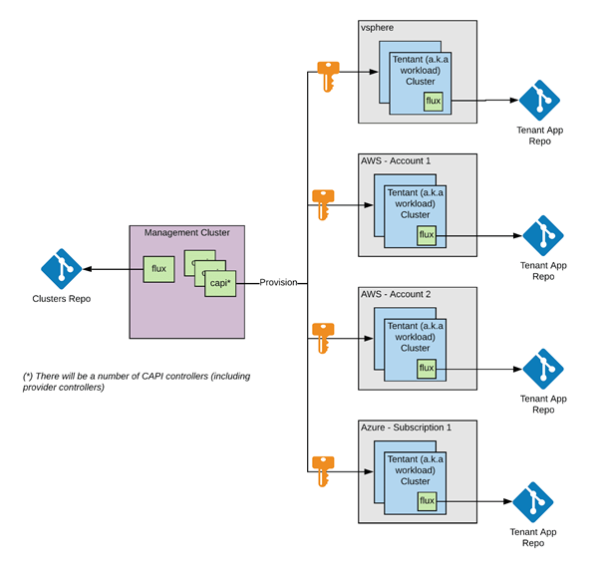
The method discussed above has no intrinsic defects. With Cluster API and Flux, achieving multi-cloud and/or hybrid scenarios is the easiest.
Multiple Clusters in GitOps
The multi-cluster manager in WKP offers the following features as part of an evolved deployment trend targeted at multi-cloud (public and/or private) and hybrid scenarios:
- Tenant clusters can only be handled from inside the target environment.
- Environment, zone, and account-level services can all be deployed. An aggregated Prometheus, for example, gathers metrics from each tenant cluster in a given context.
- In target contexts, there is more separation between cluster concepts.
- Pinpoint environments that can run separately.
Each target ecosystem has a “master management cluster” that manages the tenant clusters. Another management cluster is responsible for provisioning the master management clusters:
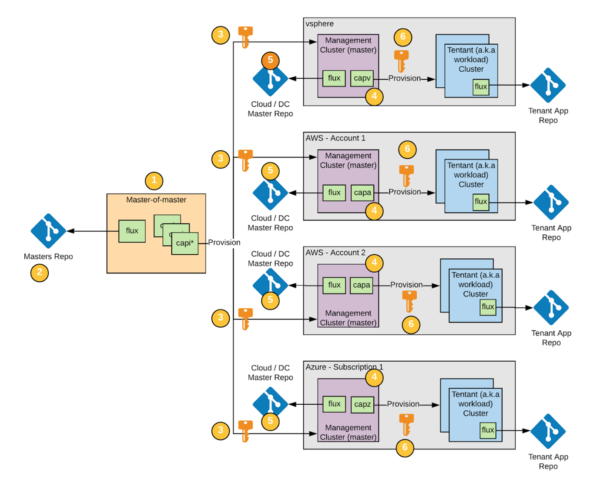
- The master management clusters are provisioned in each of the target environments by the multi-cluster management cluster. The Cluster API and providers for the target environments must be configured first. The Cluster API providers need certificates and network access to operate in the multi-cluster management cluster. Making this cluster ephemeral (perhaps with KIND or k3s) and only building it when a new target environment is necessary is an alternative. The cluster would be spun up for a brief amount of time as the current master management cluster was provisioned, and then it would be broken down.
- The cluster concepts for the master management clusters are stored in the “masters repo.” You can either use the raw YAML files or a Helm Release for this. Either the manifest or the Helm map can be applied immediately by a Flux instance operating in the multi-cluster management cluster.
- Each target setting necessitates the use of credentials. You may use either permanent or temporary passwords for these credentials. Secrets can be inserted into the cluster from Vault (using secrets engines) to be used by Cluster API providers to use short-lived credentials.
- There is a “master management cluster” in each target setting. Provisioning any tenant clusters within the setting is the responsibility of the master management cluster. It just includes the Cluster API and the provider for that setting to accomplish this (i.e. capz, capv). At least one instance of Flux will be deployed to track the “Cloud/DC Master Repo.”
- The following are the aspects of the “Cloud/DC Master Repo”:
- The tenant cluster meanings for that target environment.
- Application specifications for utilities in the target environment that can operate centrally. For instance, you may want to run log or metric aggregation for all tenants in that environment on the management cluster.
- The environment’s provider will only require certificates for that environment. Explicit passwords should not be needed if you use IAM Roles for EC2 Instances (iamInstanceProfile property in CAPA).
Conclusion
In this blog, we have discussed the essential core concepts that will be used while you get trained to code multiple-cloud operations by using GitOps on AWS. We have clearly explained concepts of operator patterns, running controllers, various states of deployments, and the concept of multi-cloud and implementing clusters in GitOps.
Author Bio
 Rajarapu Anvesh, Technical graduate in Electronics and communication engineering works as Senior content writer at Hkr Trainings. He aspires to learn new things and to grow professionally. His articles focus on the latest programming courses and E-Commerce trends. You can follow Rajarapu on LinkedIn.
Rajarapu Anvesh, Technical graduate in Electronics and communication engineering works as Senior content writer at Hkr Trainings. He aspires to learn new things and to grow professionally. His articles focus on the latest programming courses and E-Commerce trends. You can follow Rajarapu on LinkedIn.