
So, what is Watson or rather who is Watson?
Watson is an artificially intelligent computer system capable of answering questions posed in natural language, developed in IBM’s DeepQA project.
Watson is in use across a number of industries already. One of the interesting applications is Chef Watson to create unique dishes – Do you fancy Salmon taco, Tomato tart or a Russian celery sandwich?
So, I did a little experiment with some defect data from the open source gnome project that is available on the Internet.
Some of the output that from Watson is below
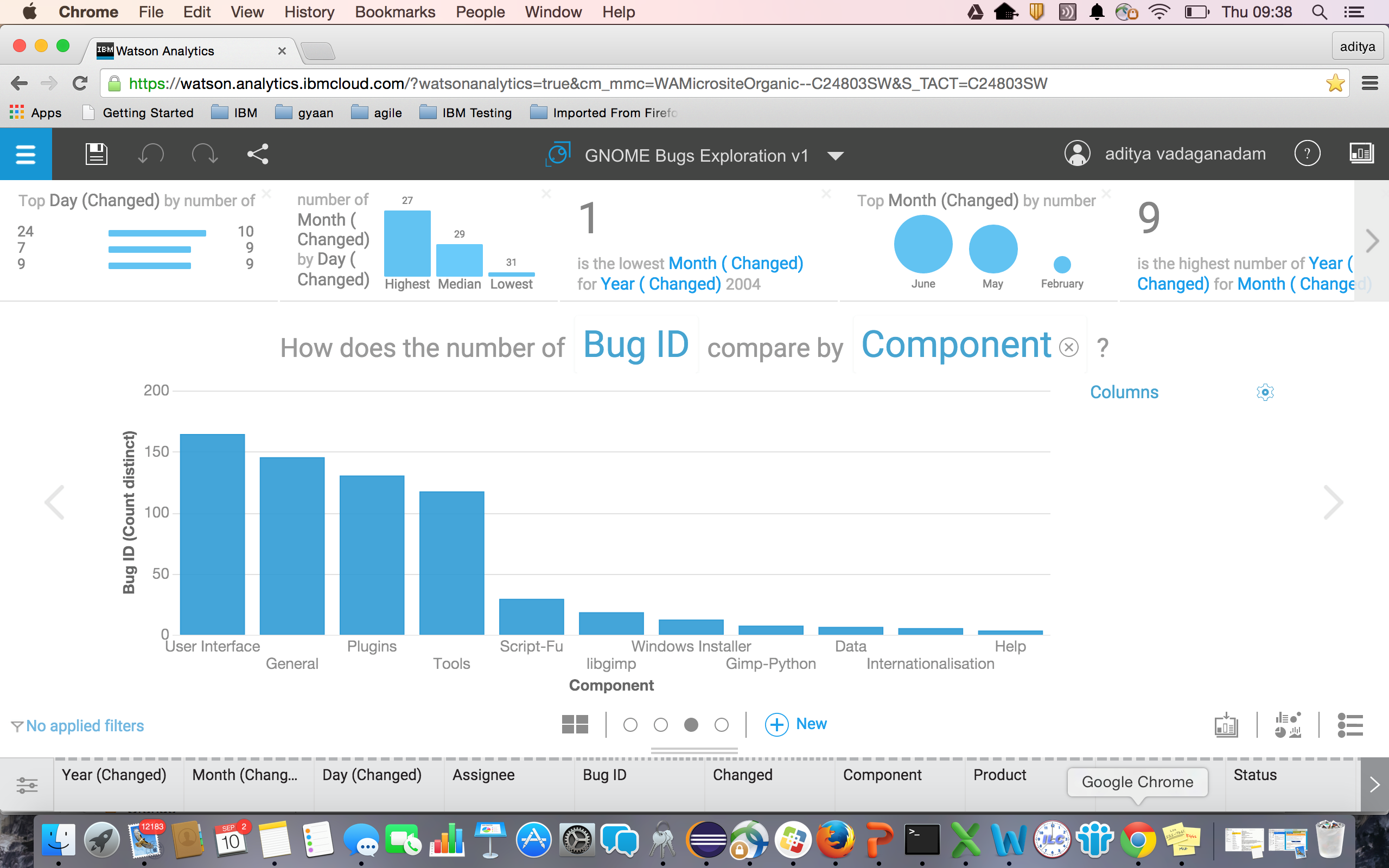
Question 1 – How does the number of Bugs compare by component?
Question 2 – What is the trend of number of Bugs over the years?
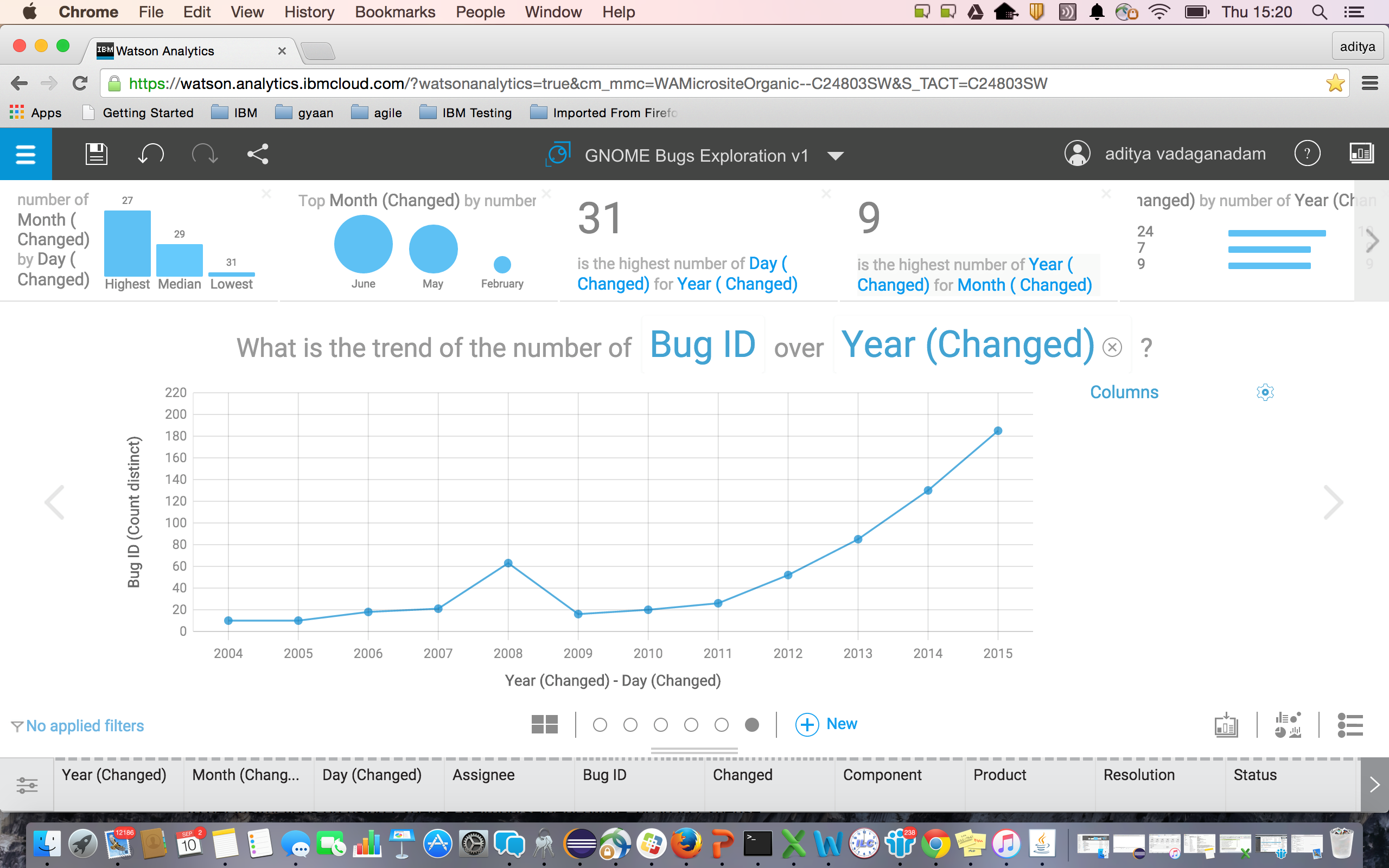
The natural language processing capability of Watson is very impressive
For instance – if you look at the query typed below in the print screen from Watson, the matching queries that Watson responded are quite relevant
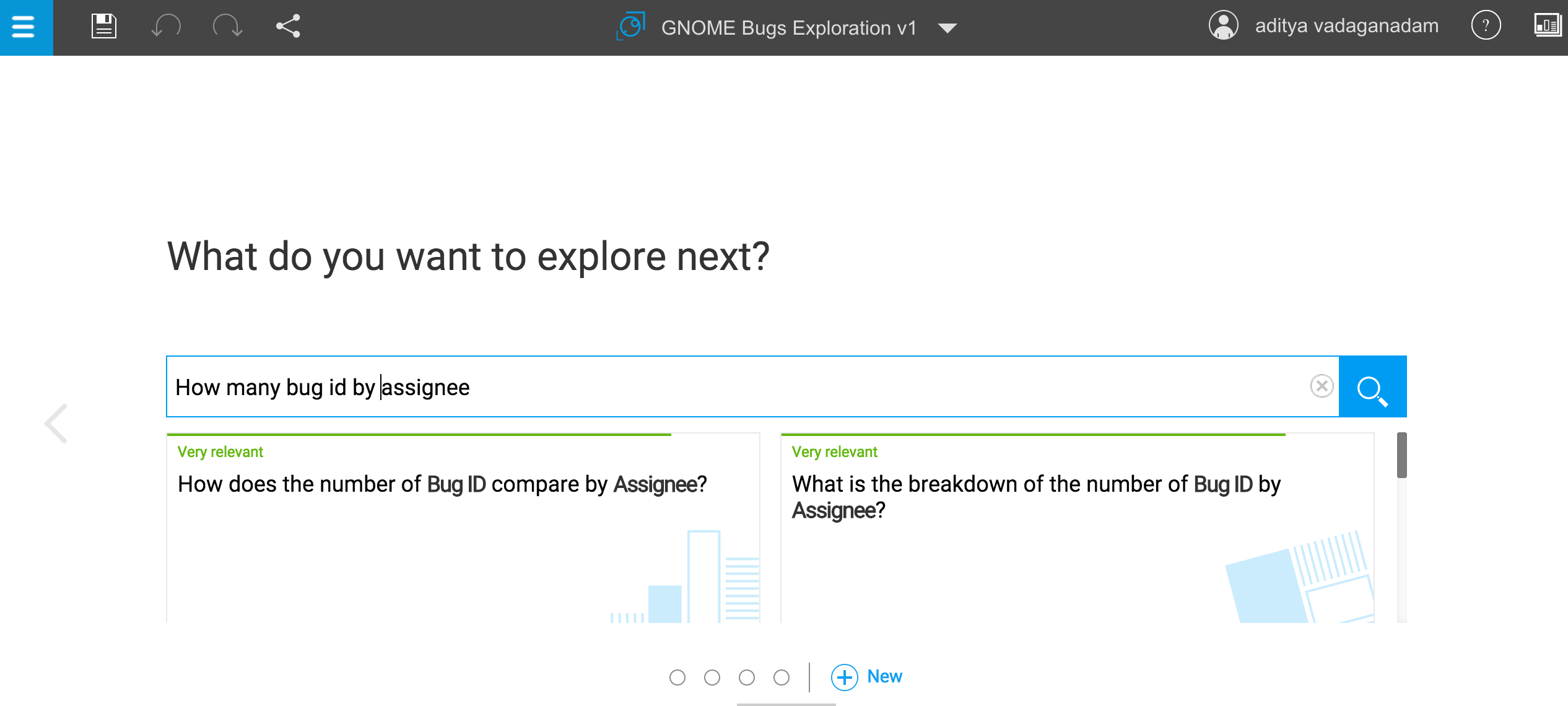
My conclusion
While the data I used is not rich enough for extensive analysis, I found the quality of the graphics, ease of use and natural language based queries of Watson very helpful. There are a number of other data visualisation and analysis tools in the market but I think Watson is the most promising of the lot.
Why don’t you give it a spin, do you have some defect data with lot more content and columns of data that you can try on Watson?